
周末,炸锅了!美国AI圈被中国大模型惊到了。
尽管中国购买先进制程的芯片面临种种限制,但有迹象表明,中国初创企业追赶美国领先的AI模型的速度要比业内许多人预期的更快。
最近,国产AI大模型DeepSeek-V3版本正式发布,其性能相当强悍,经初步评测,已经与GPT-4o、Claude-3.5-sonnet推理能力相当,编程能力甚至媲美最领先的3.5 Sonnet,超过GPT-4o。
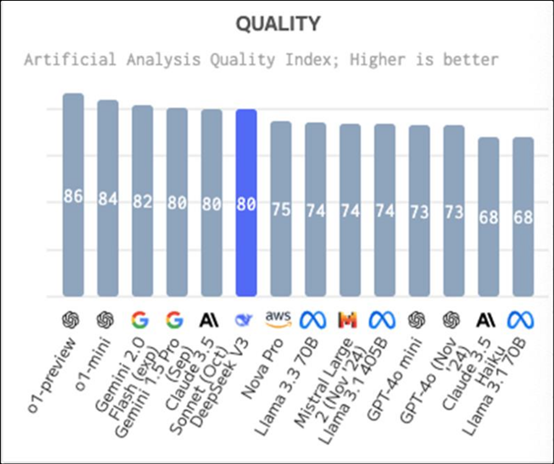
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
最引人注目的是DeepSeek-V3的低成本优势。根据开源论文披露,按每GPU小时2美元计算,模型全部训练成本仅为557.6万美元,是Llama-3405B超6000万美元训练成本的十分之一不到。
训练仅花费558万美元,算力不重要了?
这一突破性成果得益于算法、框架和硬件的协同优化。
而算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。特别是推理测需求有望加速。$博时恒生科技ETF发起式联接(QDII)C(OTCFUND|014439)$ $博时沪深300ETF发起式联接C(OTCFUND|022600)$ $博时中证A500ETF联接C(OTCFUND|022458)$ #宇树机器狗引发热议 ,机器人风口再起?#
郑重声明:用户在基金吧/财富号/股吧社区发表的所有信息(包括但不限于文字、视频、音频、数据及图表)仅代表个人观点,与本网站立场无关,不对您构成任何投资建议,据此操作风险自担。请勿相信代客理财、免费荐股和炒股培训等宣传内容,远离非法证券活动。请勿添加发言用户的手机号码、公众号、微博、微信及QQ等信息,谨防上当受骗!
评论该主题
帖子不见了!怎么办?作者:您目前是匿名发表 登录 | 5秒注册 作者:,欢迎留言 退出发表新主题
郑重声明:用户在社区发表的所有资料、言论等仅代表个人观点,与本网站立场无关,不对您构成任何投资建议。用户应基于自己的独立判断,自行决定证券投资并承担相应风险。《东方财富社区管理规定》
