
过节期间,各路人士对美联储降多少BP的分析没有引起我的兴趣,但OpenAI默默上线了新模型,本来没多少期待的我,又惊喜到了。
着急看结论的朋友,去文末看“总结”。但正文有两段重点,建议大家看看,可以对整个事情有更感性的理解。
—— 正文,开始 ——
新模型o1-preview,我已经帮大家测过了。
结论就是:(!!!重点!!!)
这一轮制约大模型应用的最大短板——逻辑推理能力,即将被OpenAI补完。
来看我找的一道数学证明题。

只用1次输入,o1模型自动完成思考过程,直接给出推理结果。
换成以前GPT-4o这些模型,需要手动输入思维链,先把问题拆解成很多小问题,一步一步的喂给模型,然后得出答案。
并且这个答案还可能是错的。
但现在,思维链已经可以有o1模型自动完成了,中间不需要用户手动提示。
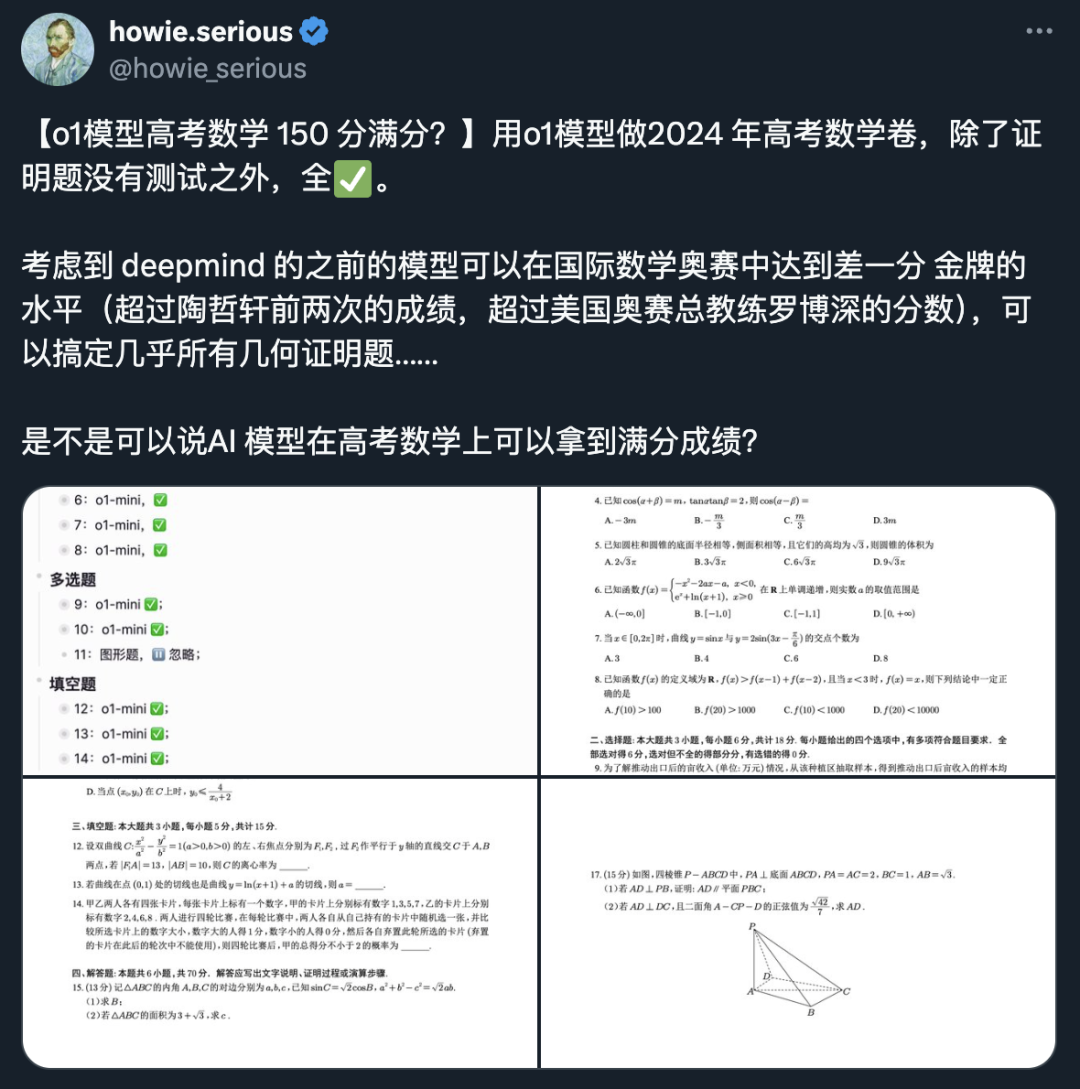
如果觉得我这题还不够有说服力,可以看看网友的测试,最新的2024高考数学卷,o1模型考了满分。
证明题没做,是因为目前o1只具备推理+文字输入输出的能力,还不具备4o这种能输入、输出图片的多模态能力。
之所以o1能达成这样的效果,是因为模型有快和慢两套系统。
以前的模型只有“快系统”,
你输入提示词,
模型思考(计算)一次,
给出结果,结束。
所以,如果你想提高模型输出结果的效果,要把复杂的问题手动拆成简单的问题。
现在o1的“慢系统”,代替了你手动输入思维链的工作。
这意味着,o1不再是你输入一次,它计算一次,给出结果的工作流程。
而是,
你输入一次,
它用“快系统”计算一次,
再用“慢系统”计算N次(取决于需要多少步思维链,即模型的思考过程变长了),
然后给出结果,结束。
代替手动输入的好处是,对于大部分用户来说,想把一个问题拆成N个准确表达的小问题,并且问题之间还存在逻辑关系,是很高的门槛,也是提示词工程一直有效的原因。
现在“慢系统”把这个门槛降低了,并且自动化了。
代价就是:
1、思考需要时间,所以o1需要先考虑个几十秒到一两分钟,再给出结果。
但这并不是缺点,思考越充分,对解决复杂问题的帮助越大。
OpenAI的下一目标是延长模型的思考时间,让模型有解决更加复杂问题的能力。
2、对算力消耗巨大,因为思考步骤多。
新模型有两个版本,
一个是知识更全面参数量更大的o1-preview,9月12号上线时候,1周只能对话30次,昨天加了一点,1周能对话50次。
另一个是知识没那么全面参数量相对小一些,但是更便宜的o1-mini,刚上线的时候1周只能对话50次,昨天加到1天可以对话50次。
而4o的plus用户,可以每3小时对话80次。
意思是,OpenAI目前的算力,完全不够这两个模型畅聊的,新模型的算力成本至少是指数级的提升。
仿佛一夜回到两年前,ChatGPT刚发布的时候,每次对话都要精打细算,一不小心就超标了。
新模型o1如何让堆算力继续生效:(!!!重点!!!)
大模型学会的所有能力,都来自于它的训练数据,数据里没有的东西,是它无论如何都学不会的。
之前硅谷那边有消息说,目前在模型训练阶段堆算力scaling law的效果在下降。
因为高质量的数据不够了,网上能爬取的基本都被训练完了。
所以,继续堆算力,模型的能力提升幅度也依然在下降。
这里面有两个可以打破僵局的因素:
1、能提供更多新的高质量数据。
2、在训练之外的环节,增加模型的效果,主要指的就是推理。
而现在,这两件事,都在OpenAI这次最新的o1模型上实现了。
第一,这次模型使用了新的合成数据,这让可以训练的数据量增加了。
它带来的结果是:模型在训练阶段的算力需求还能继续增长,还能scaling law。
训练模型所需要的算力,如下:

使用合成数据,就是让训练数据量D继续增长。
在模型参数P不变的前提下,训练数据量D增长,则训练模型需要的算力C就会增长。
第二,我认为比第一点更重要,是这次o1模型在推理阶段加大了算力资源的投入,并且取得了很好的效果,模型的逻辑推理能力大幅提升。
它带来的结果是:一条新的scaling law路径出现了。
过去在训练端狂堆算力是提升模型效果最好的方式,现在,当训练端堆算力堆到瓶颈后,接着在推理端堆算力,可以继续提升模型能力。
模型推理所需要的算力,如下:

“慢系统”的有效,就是主动提升运算次数T,来提升模型效果。
在模型参数量P不变的前提下,提升运算次数T,模型在推理时需要的算力C就会增长。
—— 总结 ——
1、OpenAI的新模型o1,逻辑推理能力大幅提升,效果显著。
2、在技术层面,提供了大模型堆算力的新路径:过去在训练阶段堆算力,今后可以在推理阶段堆算力。
3、无论哪种路径,堆到一定程度后,效果都会递减,但在推理阶段堆算力,以前没搞过,是从这一次之后才开始,还能堆一阵子。
4、等竞品公司研究明白OpenAI的技术之后,应该会大量跟随复制。OpenAI只能短时间领先,但不可能长时间垄断这项技术。这意味着,一旦复制开始,堆算力的需求可能又会增长。
5、最重要的是,这一次模型逻辑推理能力的提升,可能更广泛的推动AI解决真实问题,我们希望看到的AI应用商业化,这一步迈的挺大。随着对新模型的体验加深,我会有新的感受,到时候再跟大家分享这个商业化的潜力。
6、对于美股,目前我的计划就是不动。我并不想逃顶,因为仓位不算重,现在也没有看到顶部的信号。
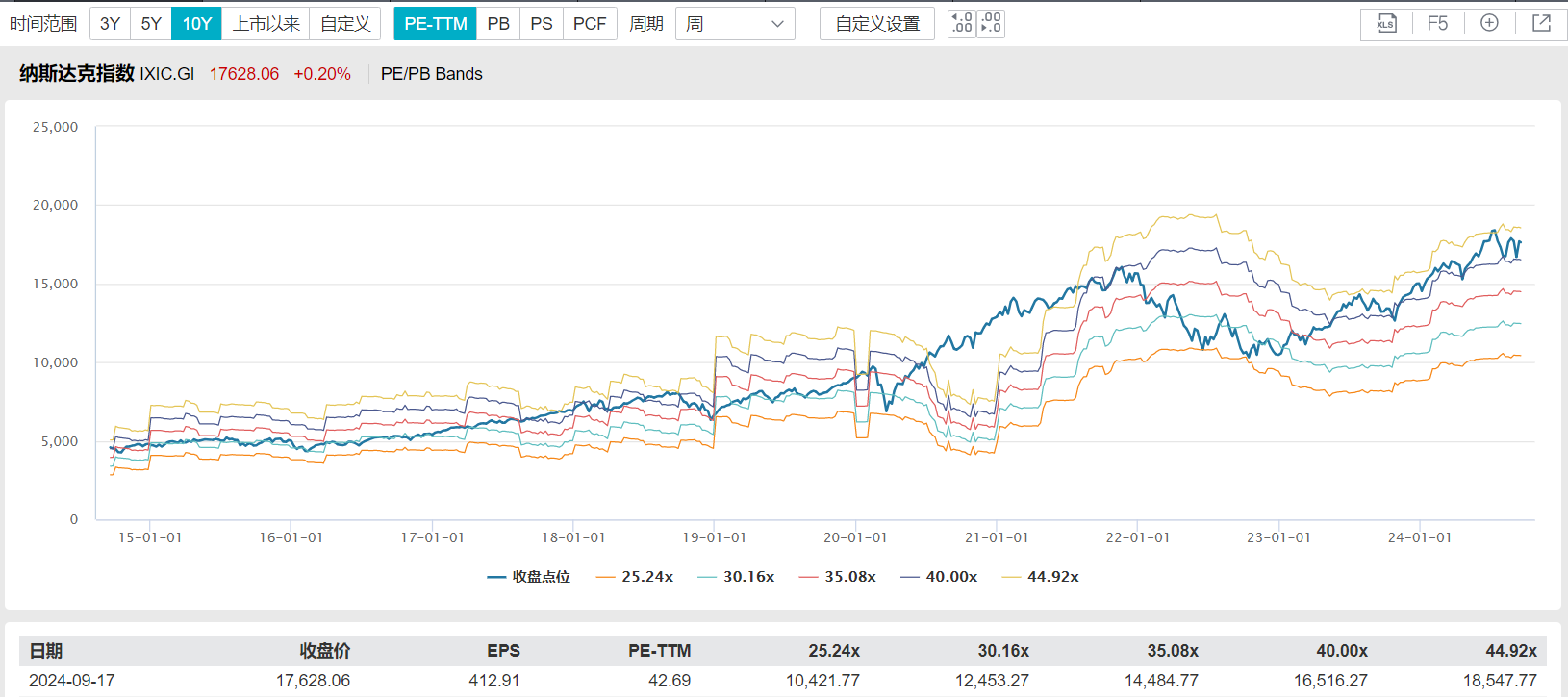
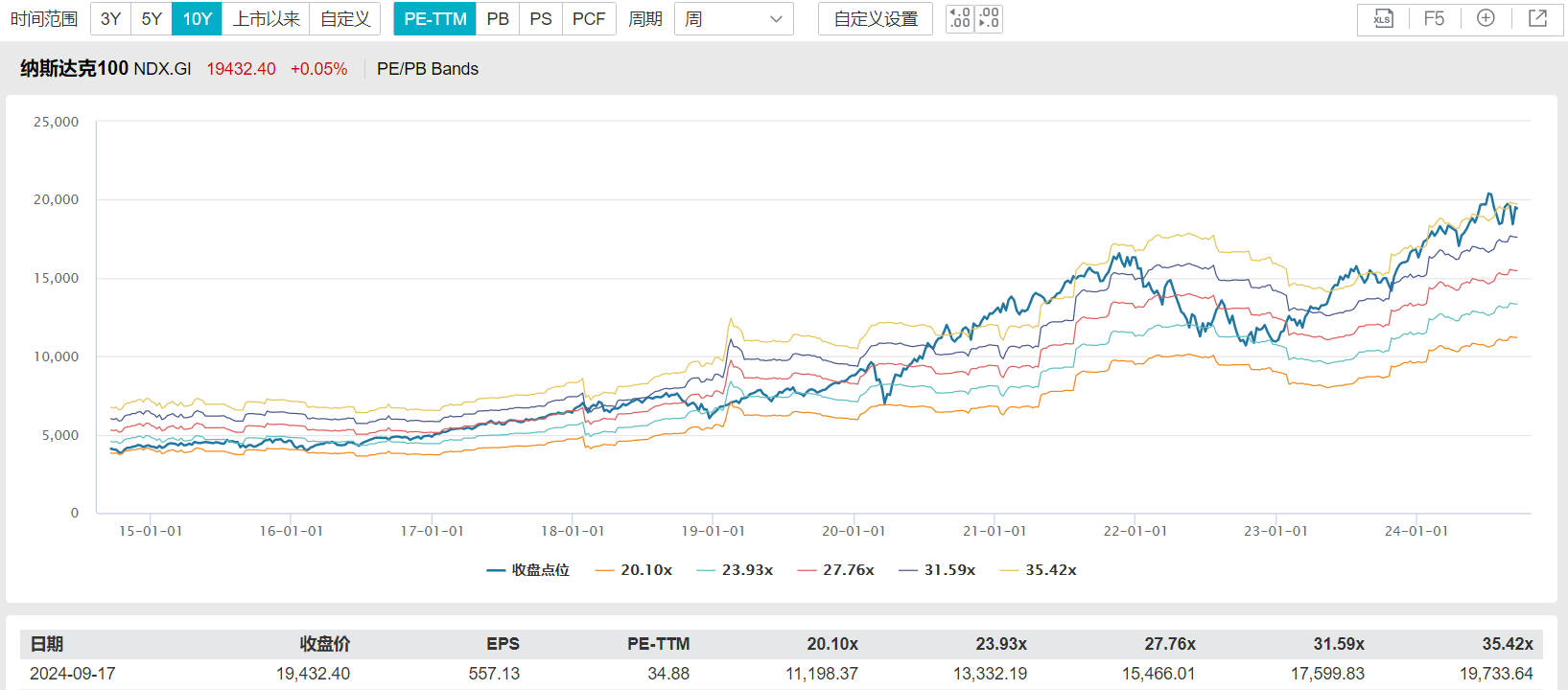
—— 每日估值:指数PE-Bands ——
纳斯达克
纳斯达克100
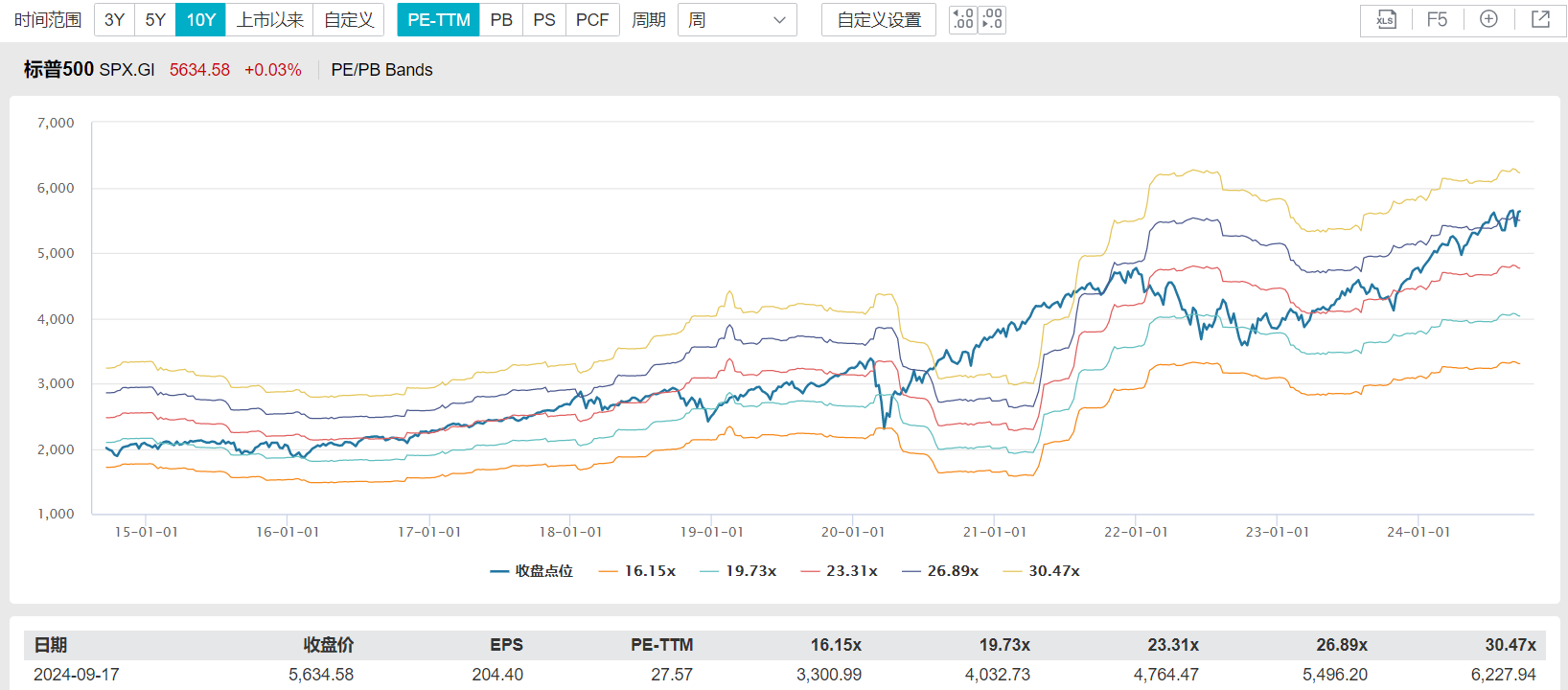
标普500
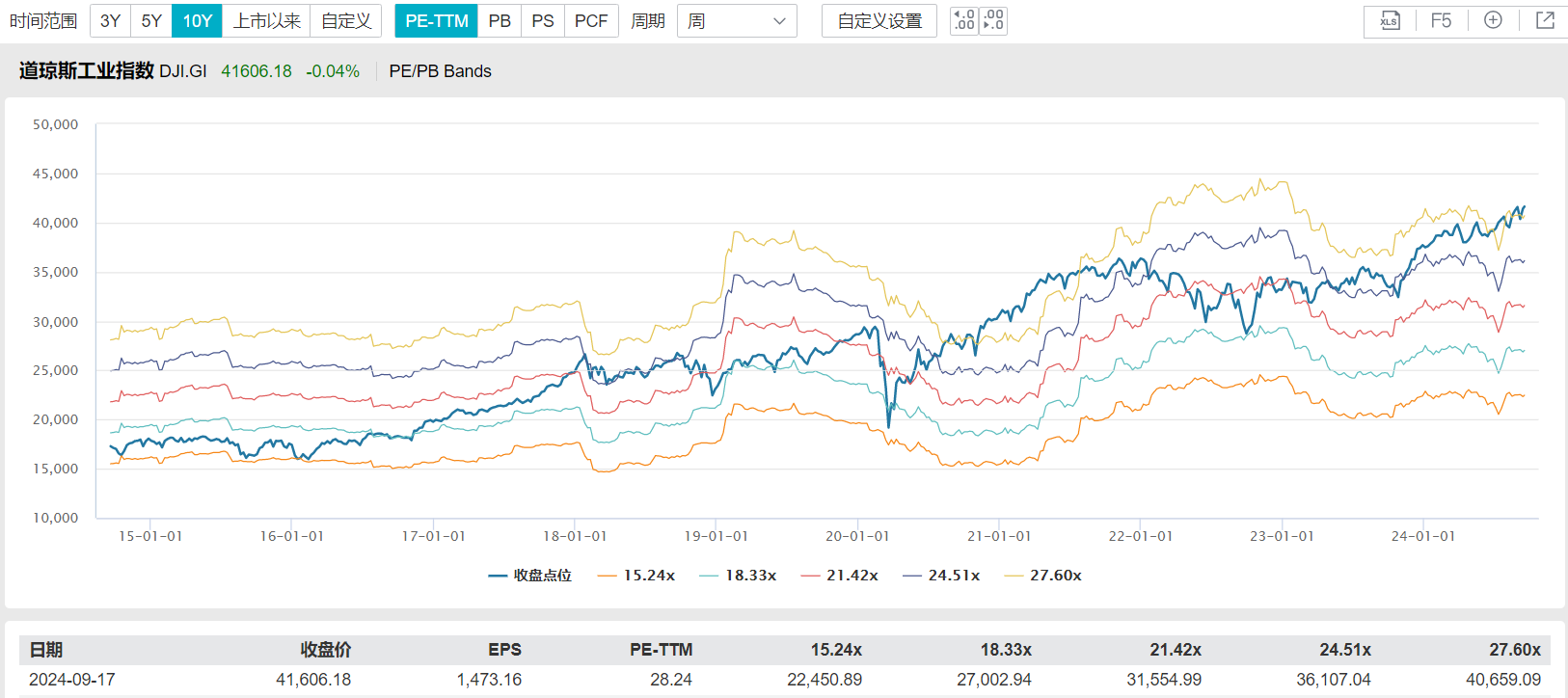
道琼斯工业
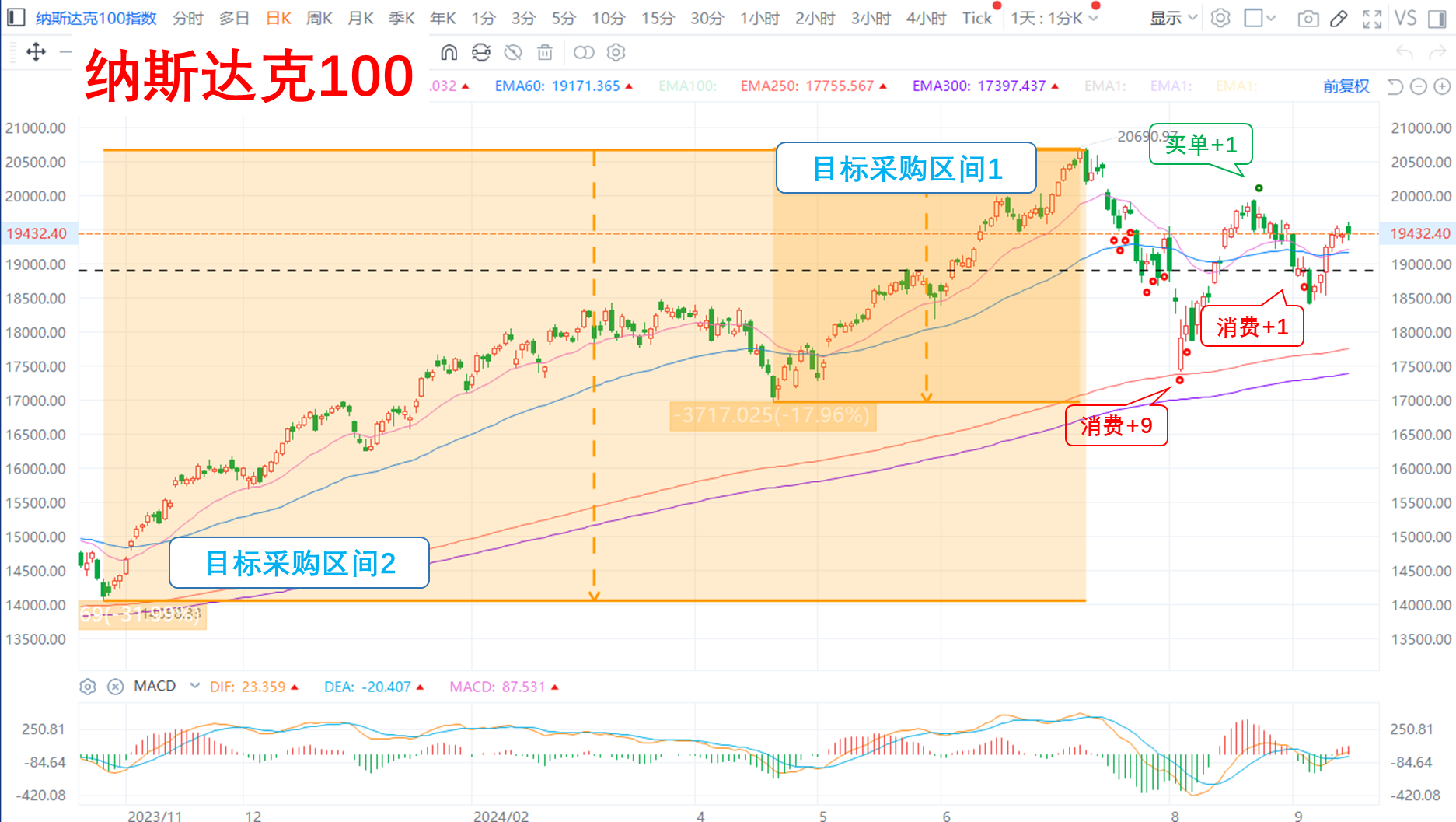
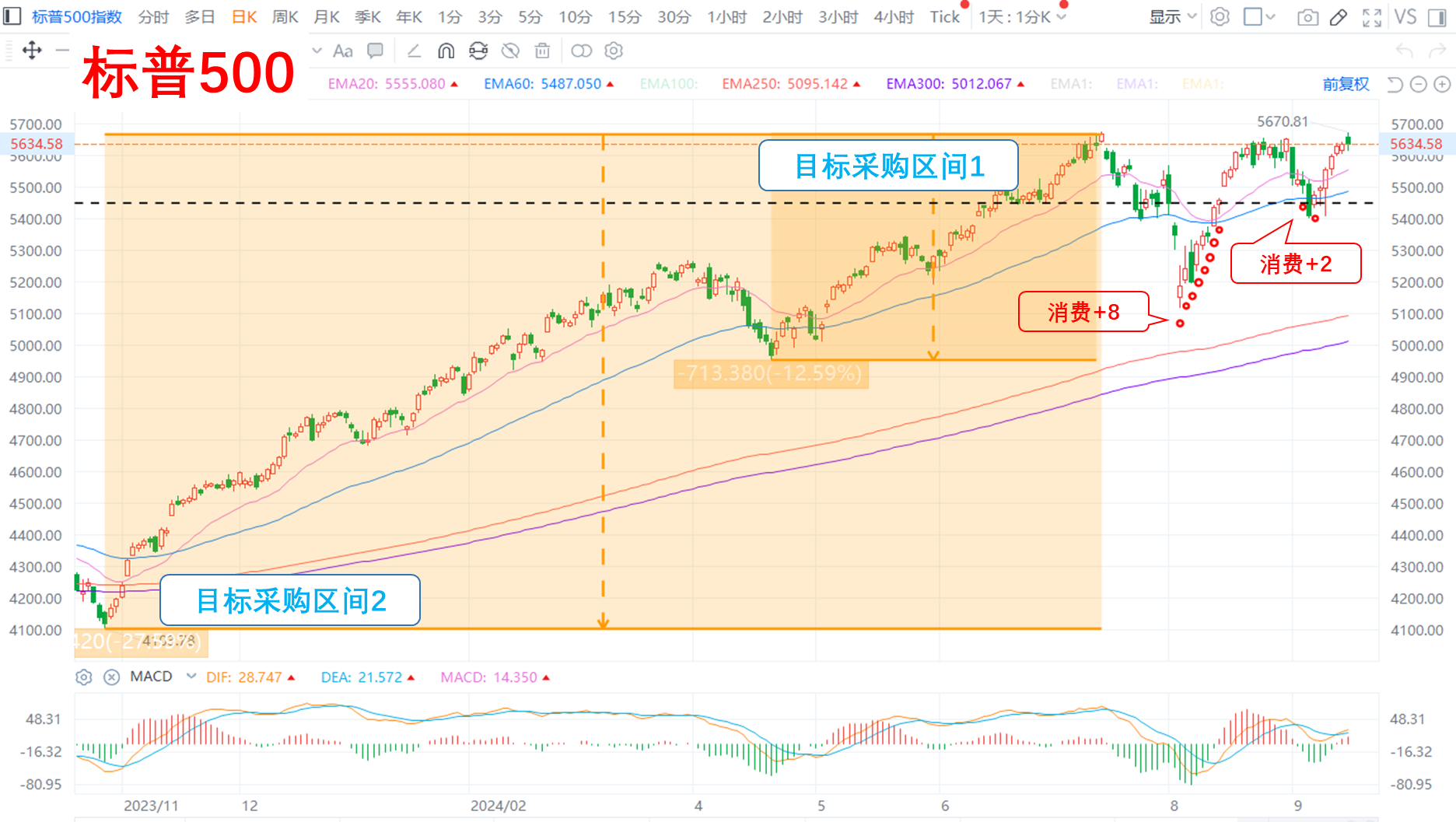
—— 以下是:股市消费记录 ——
美股:
**纳指:等待……
**标普:等待……
国内:
目前处于休息状态。
*** 做合格金融消费者,从记账开始!***
海外消费记录:
Ps:在国内盘中下的美股QDII订单,对应的是当日晚上的美股收盘价,实际消费值是下图标记的下一根K线。
国内消费记录:
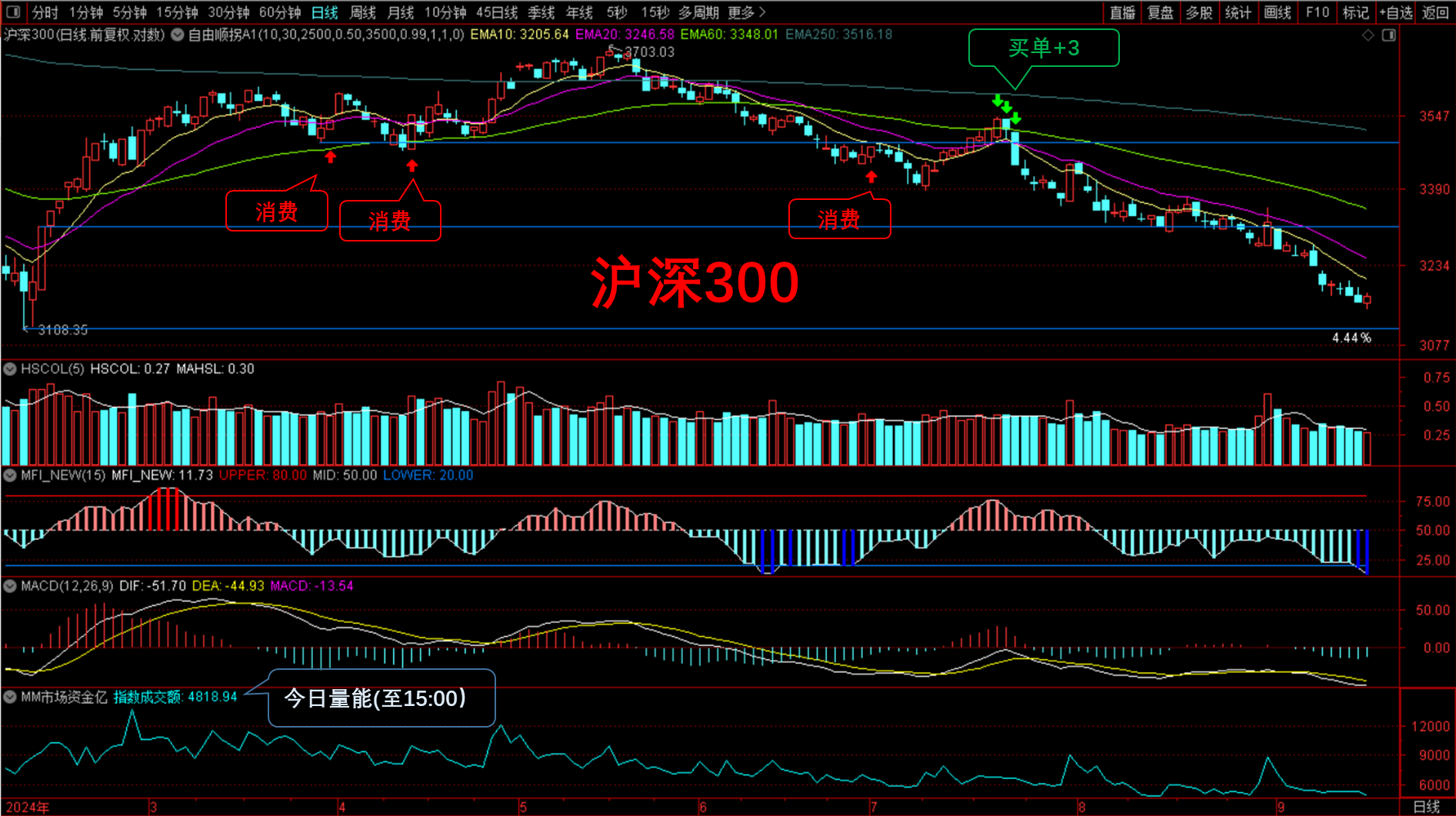
< 分享增量信息,提升决策质量。记录真实消费。如果你感兴趣,欢迎点赞关注,留言讨论,咱们交个朋友。>
风险提示:以上为个人观点,不构成买卖建议。市场有风险,投资须谨慎。
$建信纳斯达克100指数(QDII)人民币C(OTCFUND|012752)$
$广发纳斯达克100ETF联接人民币(QDII)C(OTCFUND|006479)$
$华夏纳斯达克100ETF发起式联接(QDII)C(OTCFUND|015300)$
$华安纳斯达克100ETF联接(QDII)C(OTCFUND|014978)$
$大成纳斯达克100ETF联接(QDII)C(OTCFUND|008971)$
$南方纳斯达克100指数发起(QDII)C(OTCFUND|016453)$
$汇添富纳斯达克100ETF发起式联接(QDII)人民币A(OTCFUND|018966)$
$博时标普500ETF联接C(OTCFUND|006075)$
$华夏标普500ETF发起式联接(QDII)C(OTCFUND|018065)$
$摩根标普500指数(QDII)人民币C(OTCFUND|019305)$
