
2024年你在A股赚到钱了吗?
分到红也行。
2024年5000余家A股上市公司中,已有3972家实施了现金分红,现金分红金额合计2.39万亿元,分红公司数和分红金额创史上新高。
作为投资者,如何查询上市公司分红情况呢?
星空君推荐一个小工具:同花顺的AI助手,i问财(iwencai.com)。
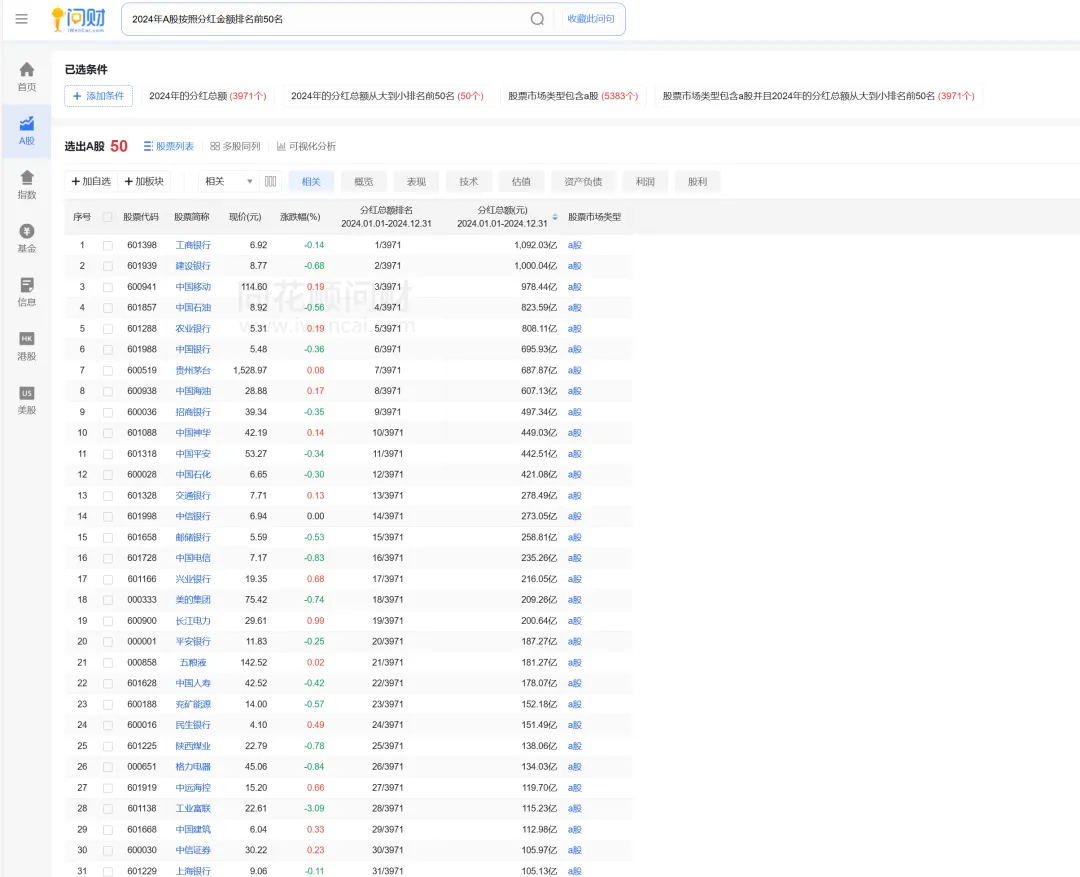
我们可以直接问i问财:2024年A股按照分红金额排名前50名。
i问财会将这个问题交给AI大模型,大模型会将自然语言进行理解,并拆解成四个条件:2024年的分红总额、2024年的分红总额从大到小排名前50名、股票市场类型包含A股、股票市场类型包含A股并且2024年分红总额从大到小排名前50名。
同花顺的数据库检索这四个条件取交集显示结果。
中国有一个非常特殊的现象:投资机构热衷搞大模型。
在六代机起飞的时候,大模型的六代机也起飞了,DeepSeekV3横空出世。
DeepSeek团队只用了2048张H800和550万美金,就成功的训练出了堪比ChatGPT-4o的大模型。
目前已经发布的DeepSeek-V3-Base仅次于OpenAIo1-2024-12-17(high),一举超越了claude-3.5-sonnet-20241022、Gemini-Exp-1206、o1-mini-2024-09-12、gemini-2.0-flash-exp等竞品模型以及前代DeepSeekChatV2.5。其中与V2.5(17.8%)相比,V3编程性能暴增到了48.4%,整整提升了近31%。

分类型来看,DeepSeek在长文本、数学、中文能力不同类型都表现出色。
- 百科知识:DeepSeek-V3在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代DeepSeek-V2.5显著提升,接近当前表现最好的模型Claude-3.5-Sonnet-1022。
- 长文本:在长文本测评中,DROP、FRAMES和LongBench v2上,DeepSeek-V3平均表现超越其他模型。- 代码:DeepSeek-V3在算法类代码场景(Codeforces)远远领先于市面上已有的全部非o1类模型;并在工程类代码场景(SWE-Bench Verified)逼近Claude-3.5-Sonnet-1022。
- 数学:在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(O 2024)上,DeepSeek-V3大幅超过了所有开源闭源模型。
- 中文能力:DeepSeek-V3与Qwen2.5-72B在教育类测评C-Eval和代词消歧等评测集上表现相近,但在事实知识C-SimpleQA上更为领先。
Kimi是文科生,通义千问是理科生,而DeepSeek则文理通吃。
要命的是,DeepSeek还开源(通义千问也有开源版本)。

当然了,对于个人用户来说,这个开源意义不大,毕竟星空君买不起H800,但对于创业企业来说,千张H800的门槛太低了吧!
昇腾觉得自己也行了!
(此处埋个彩蛋,国内用昇腾训练大模型的主力是科大讯飞)
OpenAI烧了数万张显卡耗资上百亿美金的成果,被DeepSeek团队用550万美金复刻了,而且还可能超越了。
这意味着,AI的硬件门槛不存在了。
很快,英伟达的股价将会断崖式崩塌(美股七姐妹都是靠AI一口仙气吊着)。
而DeepSeek AI的所属公司,是幻方量化。
幻方量化的技术总监、合伙人是徐进,他是浙江大学信号与信息处理博士。
巧了,同花顺的创始人易峥也毕业于浙江大学。
在很多人仰慕OpenAI感叹灯塔的时候,星空君就曾冷静的指出,OpenAI的技术并没有护城河。
它只是靠力大飞砖烧钱烧显卡证实了这条技术路线是走得通的,后续追赶的中国AI企业才能真正能把技术落地到应用场景。
只不过没想到第一个落地场景居然是投资量化,AI+量化可以把基金经理杀的片甲不留。
由于幻方不是上市公司,所以它的成绩似乎是一夜之间爆发。事实上,同花顺等互联网券商企业的财报里,早就显露出AI领域的进展。
据同花顺2023年年报:
1. 同花顺AI团队在2023年将人工智能技术在各类业务场景落地,打造多种智能服务及产品;在机器学习、NLP、语音、图像等方向取得数十项科研成果,并在国际顶级AI学术会议及期刊上发表论文十多篇;申请或授权专利共60余项。
2. 同花顺发布了业内首个金融对话大模型――问财HithinkGPT,简称“HithinkGPT”,该模型在通用领域的表现已全面超越主流开源模型Llama-2,并提供多种版本选择。
3. 同花顺在NLP的机器翻译、阅读理解、对话生成、情感分析等细分方向取得了创新技术进展,并在多个国际会议上发表论文。
4. 同花顺的语音技术在VoiceMOS Challenge 2023语音合成赛道和噪声与增强语音赛道分别排名第一和第二,相关系统论文已在ASRU 2023会议发表。
和幻方的DeepSeek走全能路线不同,同花顺的HithinkGPT走专业路线。
有理由相信,随着DeepSeek的开源,把大模型的训练成本拉到极低,中国会有更多的企业跨界做大模型,大模型将出现涌现效应。
在中国,连味精公司都能买算力卡做大模型!

在DeepSeek开源后,这一切都变得易如反掌。
AI大模型的游戏规则,被一家中国投资公司改写了。
星空君早就说过,AI大模型最终会沦为类似阿里云的服务底座,OpenAI这类公司除了倒闭或者被收购外,没有其他选择。
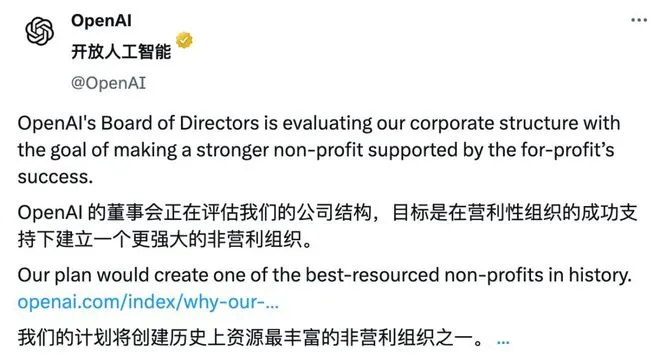
巧合的是最近OpenAI要优化架构。
官方声明指出,OpenAI 计划将从营利性公司转变为特拉华州公共利益公司(PBC)。PBC(公共利益公司)是一种特殊的营利性公司形式,要求公司在决策时平衡股东利益、利益相关者利益以及公共利益。
我们走过了漫长的摸着过河的时代,随着工业能力、技术实力、资金人才都追赶甚至超越,如今,开启了独自腾飞的新纪元,未来,将由我们来定义游戏规则。
只要能飞起来,你就不要问原因了:

(来源:诗与星空的财富号 2024-12-30 07:18) [点击查看原文]
